Artificial Intelligence (AI)
Artificial Intelligence (AI)
AI News : Scrape, Summarize, Discover
AI News : Scrape, Summarize, Discover
AI News : Scrape, Summarize, Discover
May 8, 2025
|
5
min read

Did you know we might soon be able to talk to dolphins? Yes, really. Google is working on something called DolphinGamma, a language model aimed at decoding dolphin communication. This is just one example of the kind of groundbreaking news emerging from the AI world every week. But with the rapid pace of innovation, staying updated has become increasingly difficult especially for senior leaders who don’t have time to sift through dozens of articles.
That’s why we built this AI news dashboard. It scrapes trusted sources, summarizes key updates, and presents only the most relevant insights. It helps our customers in senior management stay informed, make better decisions, and stay ahead of the curve without the noise.
What This Project Does : Overview
This project is a full-stack AI-powered content explorer that simplifies how users discover and consume quality information about Artificial Intelligence. Instead of manually searching the web, users are presented with clean summaries of top AI blog posts all through a fast, elegant web interface.
At a high level:
A Python backend manages article scraping, AI-based summarization, and API endpoints.
A Supabase database stores summarized content and metadata.
A modern React.js frontend (with Tailwind CSS and TypeScript) enables users to select blog categories and explore summaries with ease.

Fundamental Technical Elements
Before diving into the technologies used to build the platform, it is essential to understand the core technical components that define how the system operates. Each of these elements plays a specific role in enabling the end-to-end flow — from content discovery to summarization and delivery to users.
We begin with one of the system’s most foundational components: web scraping.
Web Scraping
Web scraping is the automated process of extracting data from websites.it refers to “the use of computer software to collect information from websites without a direct API or structured data feed”
In the context of our system, web scraping is a critical entry point: it is responsible for continuously gathering fresh content from predefined AI blog sources. Whether through RSS feeds or direct HTML parsing, the scraper ensures that we stay up to date with the latest publications relevant to the AI community.
How It Works Technically
The scraping logic is handled by an asynchronous Python service that uses a combination of:
requests+BeautifulSoupfor static sitesplaywright.async_apifor dynamic websites that require JavaScript rendering
Here’s a simplified version of how article links are extracted from a given blog source:
from playwright.async_api import async_playwright from bs4 import BeautifulSoup import requests async def fetch_article_links(source_url: str, is_dynamic: bool = False): if is_dynamic: async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() await page.goto(source_url) content = await page.content() await browser.close() else: content = requests.get(source_url).text soup = BeautifulSoup(content, "html.parser")
Scheduled Execution
The scraper is executed on a fixed interval using an async background scheduler defined in timer.py.
It ensures that only one scraping job runs at a time and waits 2 minutes between cycles:
import asyncio from app.services.processor import run_pipeline scraper_lock = asyncio.Lock() async def start_scheduler(): while True: if scraper_lock.locked(): print("Previous scraping still running — skipping this cycle.") else: async with scraper_lock: await run_pipeline() await asyncio.sleep(120) # 2-minute interval
Content summarization
is the process of automatically generating a shorter version of a longer text, while preserving its key information.In our system, this step is handled by an AI-powered summarization engine that transforms full-length blog posts into concise, readable overviews. This helps users quickly understand the core message of each article without reading the full content.
How It Works Technically
The platform uses Google's Gemini 2 API, configured via the google.generativeai SDK. The system sends a carefully structured prompt that asks the model to:
Summarize the article in 3 sentences maximum
Return one or more themes from a fixed list of predefined categories
FUSION_PROMPT = "... prompt that defines summarization and theme detection tasks ..." def summarize_and_detect_theme(prompt): # Prepare request parts parts = [types.Part.from_text(text=prompt)] contents = [types.Content(role="user", parts=parts)] # Configure how Gemini should respond config = types.GenerateContentConfig( response_mime_type="application/json", response_schema=types.Schema( type=types.Type.OBJECT, properties={ "summary": types.Schema(type=types.Type.STRING), "theme": types.Schema( type=types.Type.ARRAY, items=types.Schema(type=types.Type.STRING) ) } ), system_instruction=[types.Part.from_text(text=FUSION_PROMPT)], ) # Send the request and collect the response response_text = "" for chunk in client.models.generate_content_stream( model=MODEL_NAME, contents=contents, config=config ): response_text += chunk.text result = json.loads(response_text) return result['summary'], result['theme']
Database Structure with PostgreSQL
A key part of the system's backend lies in how data is stored, structured, and accessed. Each collected blog post and its corresponding metadata is saved in a well-defined schema, ensuring traceability, consistency, and easy querying
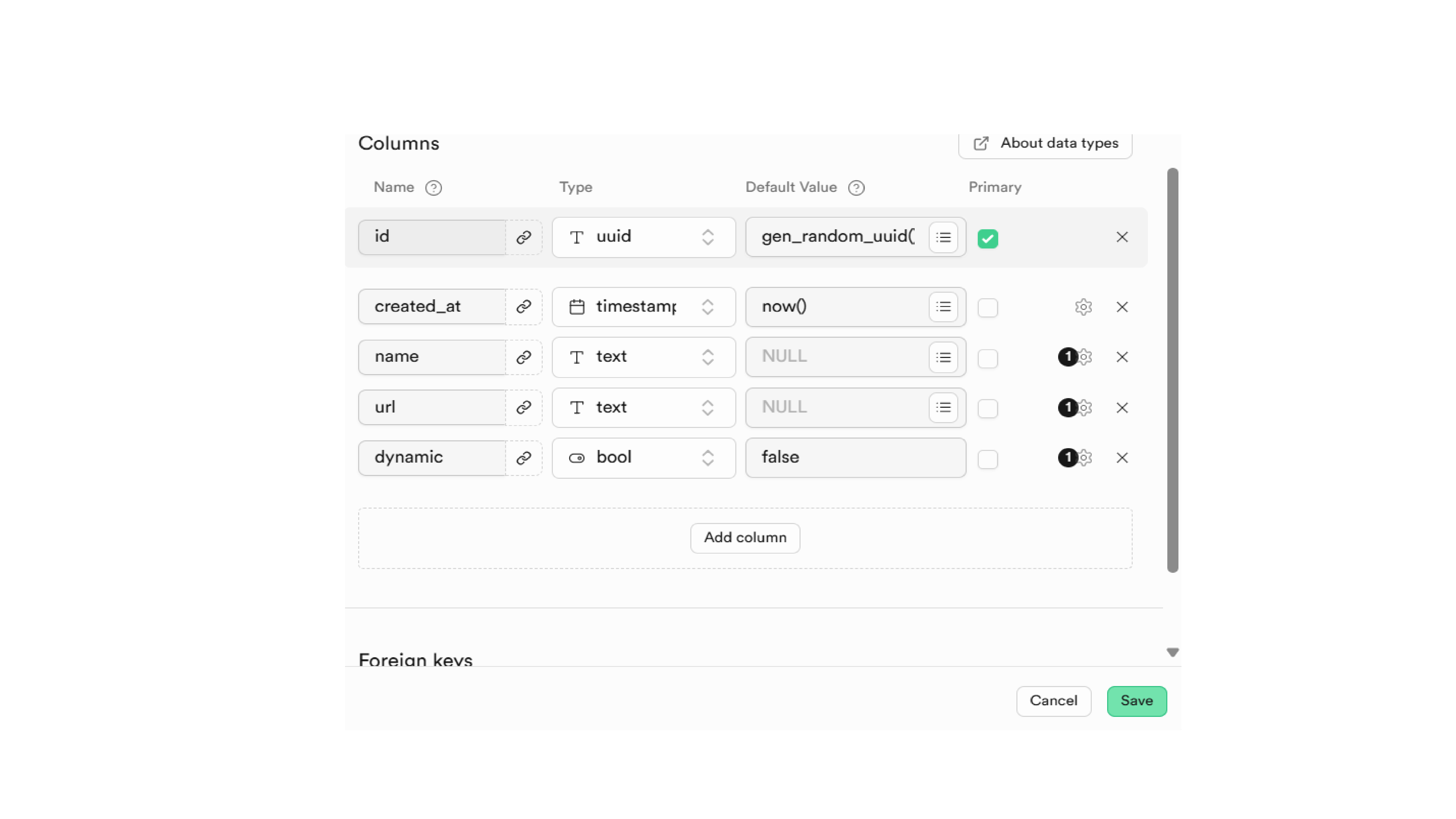
sources Table
This table keeps track of where each article comes from. It contains:
A unique source ID
A name or description of the content source
Its corresponding URL
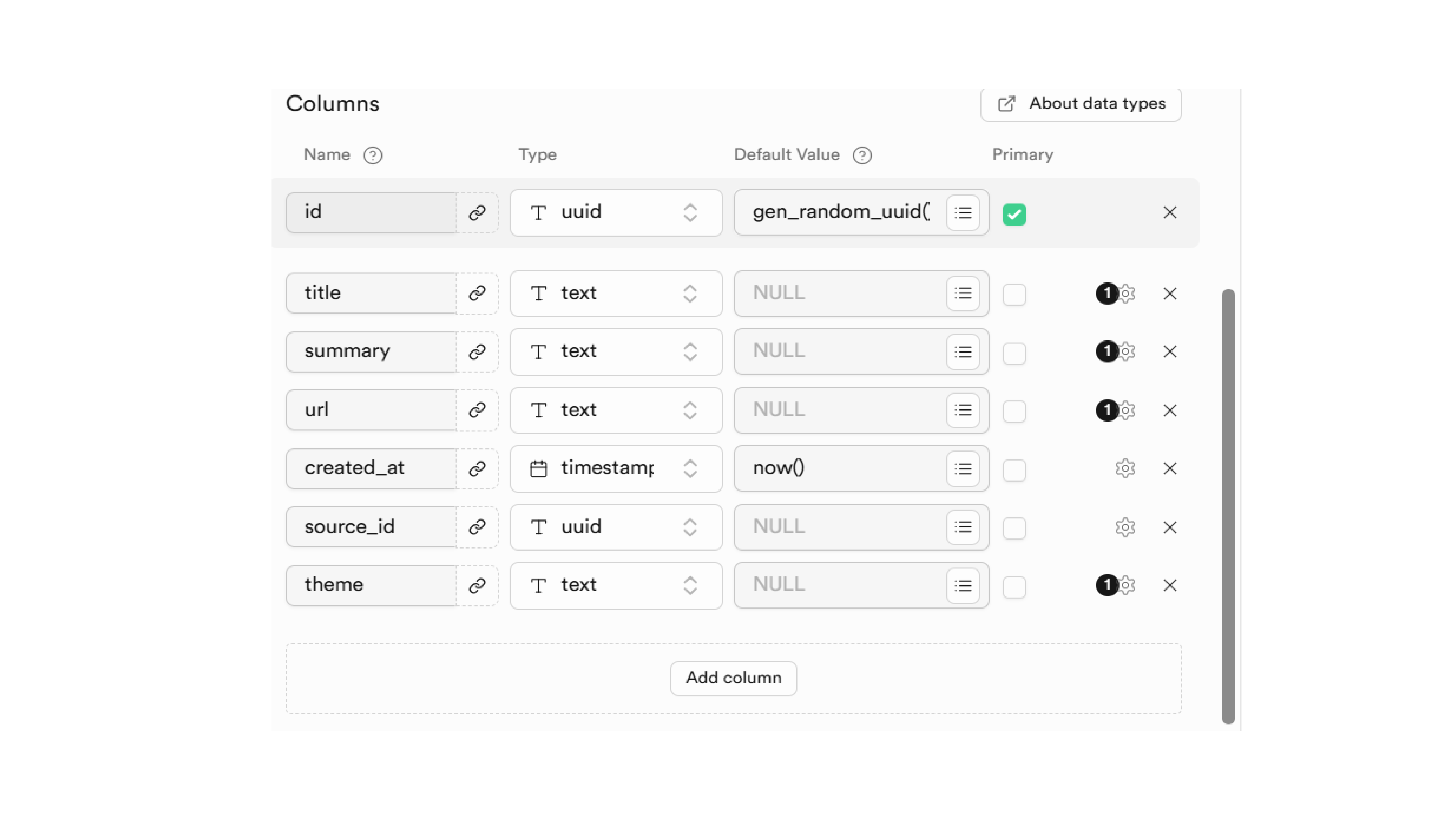
articles Table
This table is the central repository for all processed content. Each record includes:
A unique article ID
The blog post’s title and URL
An AI-generated summary
A list of thematic categories (e.g., Technology, Education)
A timestamp indicating when it was created
A reference to its origin in the
sourcestable
User Interface and API Communication
The user interface (UI) plays a central role in delivering a smooth and efficient experience. Built with React.js, styled using Tailwind CSS, and enhanced by TypeScript, the frontend offers users a modern and intuitive way to explore summarized AI content.
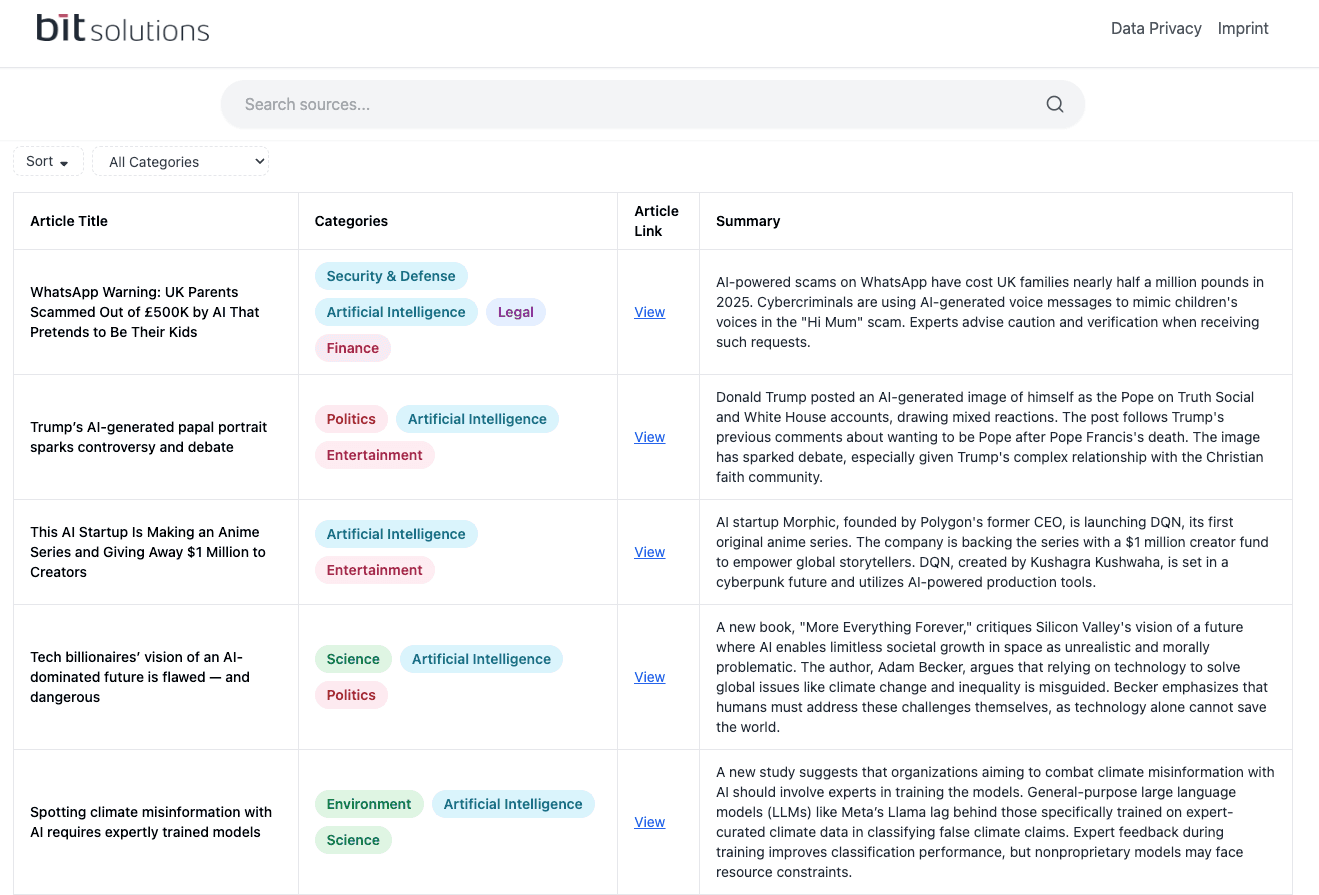
At first glance, the layout is clean and focused. Users can:
Search or filter blog posts by theme (e.g., Technology, Science, Education)
Instantly view summarized articles in a tabular format
Access the original blog post via a direct "View" link
Identify the themes associated with each article through colored labels
Data Fetching
When the component loads, it sends two requests in parallel:
tsxCopyEditconst [articlesRes, sourcesRes] = await Promise.all([ fetch('http://localhost:8000/articles'), fetch('http://localhost:8000/sources') ])
It filters out any article where summarization failed and stores the result using useState.
Filtering and Sorting
Users can:
Sort articles alphabetically using a toggle button
Filter articles by category using a dropdown
Try the Demo
Curious to see it in action? We’ve made a live demo available so you can explore the dashboard yourself.
Check out the AI News Dashboard on Vercel
Note: This demo runs on a free tier and may take a few seconds to load.
Did you know we might soon be able to talk to dolphins? Yes, really. Google is working on something called DolphinGamma, a language model aimed at decoding dolphin communication. This is just one example of the kind of groundbreaking news emerging from the AI world every week. But with the rapid pace of innovation, staying updated has become increasingly difficult especially for senior leaders who don’t have time to sift through dozens of articles.
That’s why we built this AI news dashboard. It scrapes trusted sources, summarizes key updates, and presents only the most relevant insights. It helps our customers in senior management stay informed, make better decisions, and stay ahead of the curve without the noise.
What This Project Does : Overview
This project is a full-stack AI-powered content explorer that simplifies how users discover and consume quality information about Artificial Intelligence. Instead of manually searching the web, users are presented with clean summaries of top AI blog posts all through a fast, elegant web interface.
At a high level:
A Python backend manages article scraping, AI-based summarization, and API endpoints.
A Supabase database stores summarized content and metadata.
A modern React.js frontend (with Tailwind CSS and TypeScript) enables users to select blog categories and explore summaries with ease.
Fundamental Technical Elements
Before diving into the technologies used to build the platform, it is essential to understand the core technical components that define how the system operates. Each of these elements plays a specific role in enabling the end-to-end flow — from content discovery to summarization and delivery to users.
We begin with one of the system’s most foundational components: web scraping.
Web Scraping
Web scraping is the automated process of extracting data from websites.it refers to “the use of computer software to collect information from websites without a direct API or structured data feed”
In the context of our system, web scraping is a critical entry point: it is responsible for continuously gathering fresh content from predefined AI blog sources. Whether through RSS feeds or direct HTML parsing, the scraper ensures that we stay up to date with the latest publications relevant to the AI community.
How It Works Technically
The scraping logic is handled by an asynchronous Python service that uses a combination of:
requests+BeautifulSoupfor static sitesplaywright.async_apifor dynamic websites that require JavaScript rendering
Here’s a simplified version of how article links are extracted from a given blog source:
from playwright.async_api import async_playwright from bs4 import BeautifulSoup import requests async def fetch_article_links(source_url: str, is_dynamic: bool = False): if is_dynamic: async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() await page.goto(source_url) content = await page.content() await browser.close() else: content = requests.get(source_url).text soup = BeautifulSoup(content, "html.parser")
Scheduled Execution
The scraper is executed on a fixed interval using an async background scheduler defined in timer.py.
It ensures that only one scraping job runs at a time and waits 2 minutes between cycles:
import asyncio from app.services.processor import run_pipeline scraper_lock = asyncio.Lock() async def start_scheduler(): while True: if scraper_lock.locked(): print("Previous scraping still running — skipping this cycle.") else: async with scraper_lock: await run_pipeline() await asyncio.sleep(120) # 2-minute interval
Content summarization
is the process of automatically generating a shorter version of a longer text, while preserving its key information.In our system, this step is handled by an AI-powered summarization engine that transforms full-length blog posts into concise, readable overviews. This helps users quickly understand the core message of each article without reading the full content.
How It Works Technically
The platform uses Google's Gemini 2 API, configured via the google.generativeai SDK. The system sends a carefully structured prompt that asks the model to:
Summarize the article in 3 sentences maximum
Return one or more themes from a fixed list of predefined categories
FUSION_PROMPT = "... prompt that defines summarization and theme detection tasks ..." def summarize_and_detect_theme(prompt): # Prepare request parts parts = [types.Part.from_text(text=prompt)] contents = [types.Content(role="user", parts=parts)] # Configure how Gemini should respond config = types.GenerateContentConfig( response_mime_type="application/json", response_schema=types.Schema( type=types.Type.OBJECT, properties={ "summary": types.Schema(type=types.Type.STRING), "theme": types.Schema( type=types.Type.ARRAY, items=types.Schema(type=types.Type.STRING) ) } ), system_instruction=[types.Part.from_text(text=FUSION_PROMPT)], ) # Send the request and collect the response response_text = "" for chunk in client.models.generate_content_stream( model=MODEL_NAME, contents=contents, config=config ): response_text += chunk.text result = json.loads(response_text) return result['summary'], result['theme']
Database Structure with PostgreSQL
A key part of the system's backend lies in how data is stored, structured, and accessed. Each collected blog post and its corresponding metadata is saved in a well-defined schema, ensuring traceability, consistency, and easy querying
sources Table
This table keeps track of where each article comes from. It contains:
A unique source ID
A name or description of the content source
Its corresponding URL
articles Table
This table is the central repository for all processed content. Each record includes:
A unique article ID
The blog post’s title and URL
An AI-generated summary
A list of thematic categories (e.g., Technology, Education)
A timestamp indicating when it was created
A reference to its origin in the
sourcestable
User Interface and API Communication
The user interface (UI) plays a central role in delivering a smooth and efficient experience. Built with React.js, styled using Tailwind CSS, and enhanced by TypeScript, the frontend offers users a modern and intuitive way to explore summarized AI content.
At first glance, the layout is clean and focused. Users can:
Search or filter blog posts by theme (e.g., Technology, Science, Education)
Instantly view summarized articles in a tabular format
Access the original blog post via a direct "View" link
Identify the themes associated with each article through colored labels
Data Fetching
When the component loads, it sends two requests in parallel:
tsxCopyEditconst [articlesRes, sourcesRes] = await Promise.all([ fetch('http://localhost:8000/articles'), fetch('http://localhost:8000/sources') ])
It filters out any article where summarization failed and stores the result using useState.
Filtering and Sorting
Users can:
Sort articles alphabetically using a toggle button
Filter articles by category using a dropdown
Try the Demo
Curious to see it in action? We’ve made a live demo available so you can explore the dashboard yourself.
Check out the AI News Dashboard on Vercel
Note: This demo runs on a free tier and may take a few seconds to load.
Did you know we might soon be able to talk to dolphins? Yes, really. Google is working on something called DolphinGamma, a language model aimed at decoding dolphin communication. This is just one example of the kind of groundbreaking news emerging from the AI world every week. But with the rapid pace of innovation, staying updated has become increasingly difficult especially for senior leaders who don’t have time to sift through dozens of articles.
That’s why we built this AI news dashboard. It scrapes trusted sources, summarizes key updates, and presents only the most relevant insights. It helps our customers in senior management stay informed, make better decisions, and stay ahead of the curve without the noise.
What This Project Does : Overview
This project is a full-stack AI-powered content explorer that simplifies how users discover and consume quality information about Artificial Intelligence. Instead of manually searching the web, users are presented with clean summaries of top AI blog posts all through a fast, elegant web interface.
At a high level:
A Python backend manages article scraping, AI-based summarization, and API endpoints.
A Supabase database stores summarized content and metadata.
A modern React.js frontend (with Tailwind CSS and TypeScript) enables users to select blog categories and explore summaries with ease.
Fundamental Technical Elements
Before diving into the technologies used to build the platform, it is essential to understand the core technical components that define how the system operates. Each of these elements plays a specific role in enabling the end-to-end flow — from content discovery to summarization and delivery to users.
We begin with one of the system’s most foundational components: web scraping.
Web Scraping
Web scraping is the automated process of extracting data from websites.it refers to “the use of computer software to collect information from websites without a direct API or structured data feed”
In the context of our system, web scraping is a critical entry point: it is responsible for continuously gathering fresh content from predefined AI blog sources. Whether through RSS feeds or direct HTML parsing, the scraper ensures that we stay up to date with the latest publications relevant to the AI community.
How It Works Technically
The scraping logic is handled by an asynchronous Python service that uses a combination of:
requests+BeautifulSoupfor static sitesplaywright.async_apifor dynamic websites that require JavaScript rendering
Here’s a simplified version of how article links are extracted from a given blog source:
from playwright.async_api import async_playwright from bs4 import BeautifulSoup import requests async def fetch_article_links(source_url: str, is_dynamic: bool = False): if is_dynamic: async with async_playwright() as p: browser = await p.chromium.launch() page = await browser.new_page() await page.goto(source_url) content = await page.content() await browser.close() else: content = requests.get(source_url).text soup = BeautifulSoup(content, "html.parser")
Scheduled Execution
The scraper is executed on a fixed interval using an async background scheduler defined in timer.py.
It ensures that only one scraping job runs at a time and waits 2 minutes between cycles:
import asyncio from app.services.processor import run_pipeline scraper_lock = asyncio.Lock() async def start_scheduler(): while True: if scraper_lock.locked(): print("Previous scraping still running — skipping this cycle.") else: async with scraper_lock: await run_pipeline() await asyncio.sleep(120) # 2-minute interval
Content summarization
is the process of automatically generating a shorter version of a longer text, while preserving its key information.In our system, this step is handled by an AI-powered summarization engine that transforms full-length blog posts into concise, readable overviews. This helps users quickly understand the core message of each article without reading the full content.
How It Works Technically
The platform uses Google's Gemini 2 API, configured via the google.generativeai SDK. The system sends a carefully structured prompt that asks the model to:
Summarize the article in 3 sentences maximum
Return one or more themes from a fixed list of predefined categories
FUSION_PROMPT = "... prompt that defines summarization and theme detection tasks ..." def summarize_and_detect_theme(prompt): # Prepare request parts parts = [types.Part.from_text(text=prompt)] contents = [types.Content(role="user", parts=parts)] # Configure how Gemini should respond config = types.GenerateContentConfig( response_mime_type="application/json", response_schema=types.Schema( type=types.Type.OBJECT, properties={ "summary": types.Schema(type=types.Type.STRING), "theme": types.Schema( type=types.Type.ARRAY, items=types.Schema(type=types.Type.STRING) ) } ), system_instruction=[types.Part.from_text(text=FUSION_PROMPT)], ) # Send the request and collect the response response_text = "" for chunk in client.models.generate_content_stream( model=MODEL_NAME, contents=contents, config=config ): response_text += chunk.text result = json.loads(response_text) return result['summary'], result['theme']
Database Structure with PostgreSQL
A key part of the system's backend lies in how data is stored, structured, and accessed. Each collected blog post and its corresponding metadata is saved in a well-defined schema, ensuring traceability, consistency, and easy querying
sources Table
This table keeps track of where each article comes from. It contains:
A unique source ID
A name or description of the content source
Its corresponding URL
articles Table
This table is the central repository for all processed content. Each record includes:
A unique article ID
The blog post’s title and URL
An AI-generated summary
A list of thematic categories (e.g., Technology, Education)
A timestamp indicating when it was created
A reference to its origin in the
sourcestable
User Interface and API Communication
The user interface (UI) plays a central role in delivering a smooth and efficient experience. Built with React.js, styled using Tailwind CSS, and enhanced by TypeScript, the frontend offers users a modern and intuitive way to explore summarized AI content.
At first glance, the layout is clean and focused. Users can:
Search or filter blog posts by theme (e.g., Technology, Science, Education)
Instantly view summarized articles in a tabular format
Access the original blog post via a direct "View" link
Identify the themes associated with each article through colored labels
Data Fetching
When the component loads, it sends two requests in parallel:
tsxCopyEditconst [articlesRes, sourcesRes] = await Promise.all([ fetch('http://localhost:8000/articles'), fetch('http://localhost:8000/sources') ])
It filters out any article where summarization failed and stores the result using useState.
Filtering and Sorting
Users can:
Sort articles alphabetically using a toggle button
Filter articles by category using a dropdown
Try the Demo
Curious to see it in action? We’ve made a live demo available so you can explore the dashboard yourself.
Check out the AI News Dashboard on Vercel
Note: This demo runs on a free tier and may take a few seconds to load.
